ruedli
-
Posts
4 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Everything posted by ruedli
-
Last thing I did was maintain and generate these announcement (wav) files on my computer and create a script that: - Removes all 000000000-announce and 0000000001-announce directories with their content from the USB stick from voice and music. - create 000000000-announce directories with the generated .wav announcements from tts automate, in both voice and music. - figure out the name of the file with the main theme, then create a background music file (an .ogg file) that I place in voice\0000000001-announce. This works OK, only for one soundpack it picks up the first voice from the directory with speech for the pinball, allthough my directories are alfabetically before it. I used "sox" to create a background music with 80% reduced volume. All this is executed from a powershell script, in windows 11. This seems to be the only part that I cannot resolve, maybe its a bug. I tried removing and re-adding the problematic soundpack (13 doctors for me), and tried adding more directories / files. Those did not help.
-
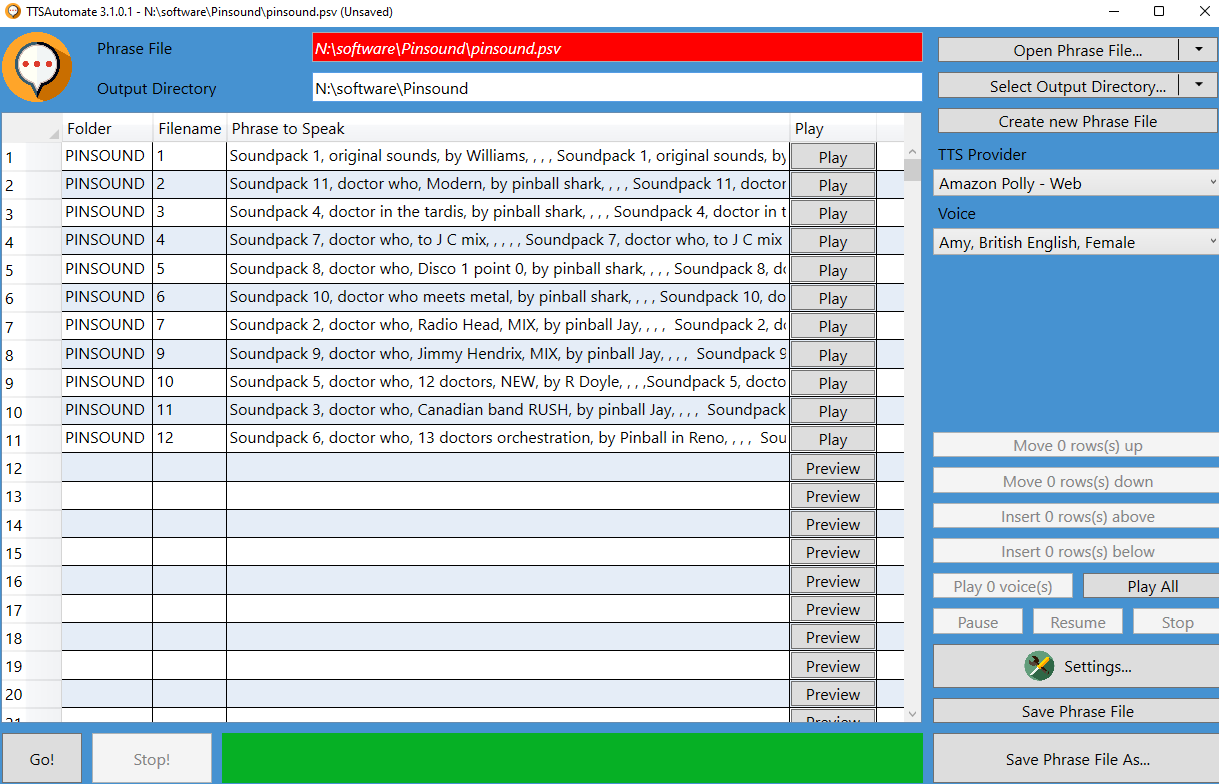
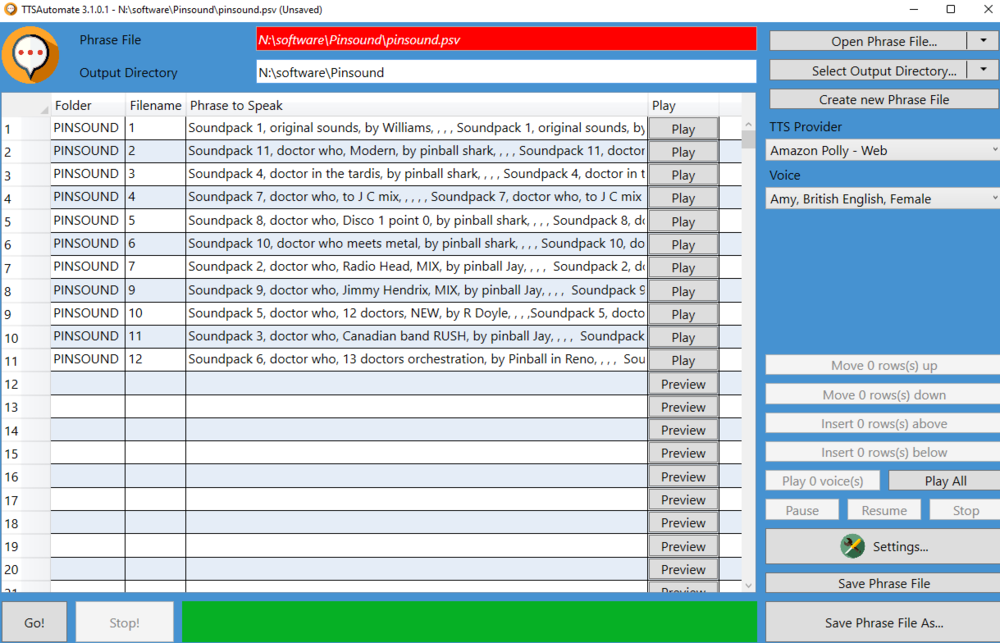
In the end, I used another tool to create the .wav files from text. TTSautomate uses text-to-speak, you can type in the text you want end get .wav files. I'll add a screen print below. I used a "strange order", because the packs are not selected in the order of loading, but in their alfabetical order. By putting these numbers in "phrase to speak" the selection goes 1,2,3,4 etc. I could get my files sorted and have the filenames reflect the soundpack sequence numbers, but in the end it doesn't matter. But.... in which directories to put them? It is sort of unpredictable. I put the appropriate .wav file in a directory 0000000000-Announce in "music" and "voice". I also add a similar directory to "single", but place an .wav file there that doesn't produce any sound. As always, I remove the buffer file, which is then created by the card. The 000000000 "just" makes sure it is the first in the list. Whereas for many sound packs this works great, for some it doesn't. Difficult to see the rules, some announcements of the soundpacks keep on playing effects or music. What is the rule here? Anyone knows the magic that is behind it? In the end I prefer a "soft" music file reflecting the theme overlaid by my generated .wav file reading out the soundpack.
-
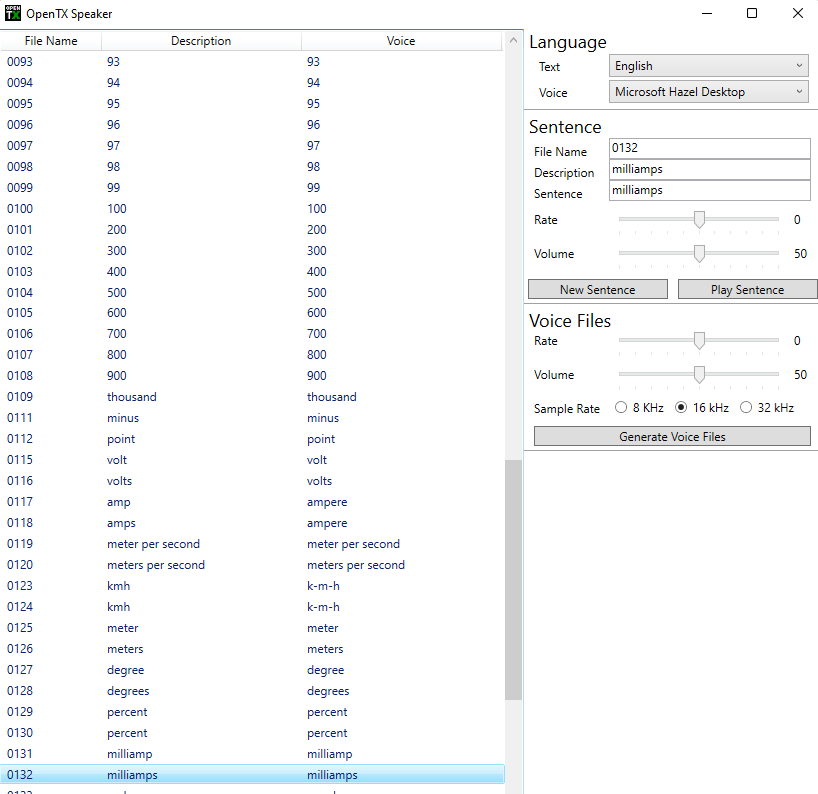
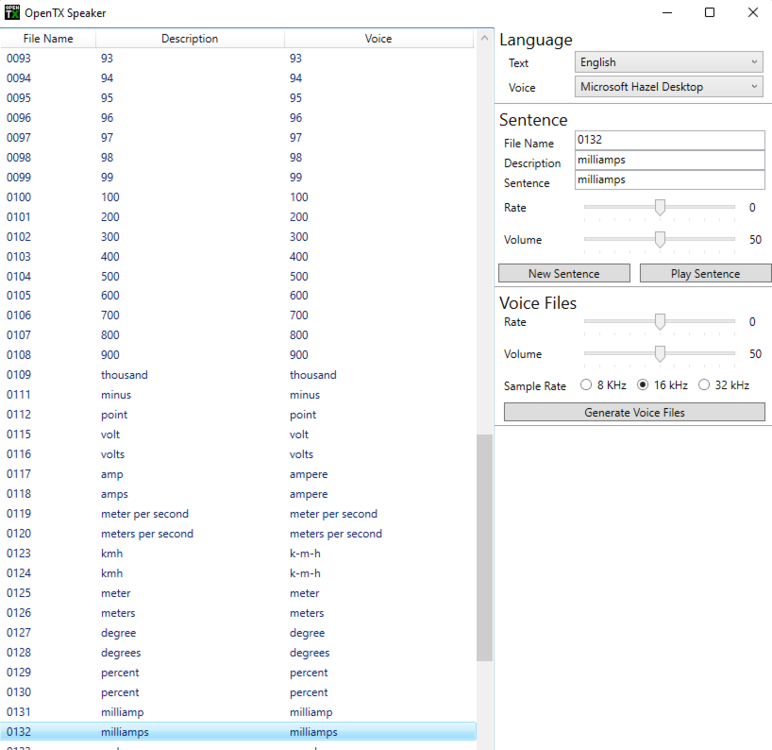
OK, I found out how to do it: In "voice" I created a directory called 0000000000-Announce in which I placed a wav file to play. You can do the same in the directory "music" and play a different tune or speech to recognize the selected card. I place a copy of the main tune in there, so it is the same type of music I can expect during playing. This file will be used when selecting the soundpack, but is not part of the pinball requested sounds. I used an utility called "OpenTX Speaker" which is used for an RC transmitter. It can produce in batch a set of WAV files that contain the sentences you type as plain text. In this way, you can let the pinball "speak" the soundset you have selected. So the "Soundpack One" etc. are generated, or just type "Soundpack one Original sounds"
-
I just asked the question if this was not already implemented: just placing files with "Soundpack one", "Soundpack two" etc. so that it is played while selecting (but not "in game". Can this be done (just installed my Pinsound Plus today)